- A famous up on YouTube recommand a book called \
- The notes covers: Why use machine learning, types of machine learning system, Main Challenges of Machine Learning
Why Use Machine Learning
- Problems for which existing solutions require a lot of hand-tuning or long lists of rules(spam filer).
Complex problems for which there is no good solution at all using a traditional approach(speech recognition).
Fluctuating environments: a Machine Learning system can adapt to new data.(speech recognition)
- Getting insights about complex problems and large amounts of data(data mining)
Types
Supervised/Unsupervised Learning
Supervised Learning
- Classification
- Regression
- Popular algorithms
- KNN
- Linear Regression
- Logistic Regression
- Support Vector Machines
- Decision Trees and Random Forests
- Neural networks(Partly)
Unsupervised learning
- popular tasks:
- cluster
- visualization
- dimensionality reduction
- anomaly detection
- Clustering
- k-means
- Hierarchical Cluster Analysis
- Expectation Maximization
- Visualization and dimensionality reduction
- PCA
- Kernel PCA
- Locally-Linear Embedding
- t-distributed Stochastic Neighbor Embedding
- Association rule learning
- Apriori
- Eclat
Semisupervised learning
- Tasks
- photo-hosting services(cluster the same person and name the person)
- Algorithms
- deep belief networks
Reinforcement Learning
- agent, the learning system observe the environment itself, select and perform actions, and get rewards or penalty in return.
Batch and Online Learning
Batch learning
- Also called offline learning, as it is trained using all the available data and apply what is has learned.
- training on the full set of data
Online learning
- feeding it data instances sequentially, either individually or by small goups called mini-batches
- good for limited computing resource: you can discard your data if the model is updated
- Learning rate is an important parameter for an online learning system, deciding how fast they should adapt to changing data or how fast it forget old data.
- Challenge: bad data feeding can greatly decline the performance of the system
- You should monitor your system closely and promptly switch learning off.
Instance/Model Based Learning
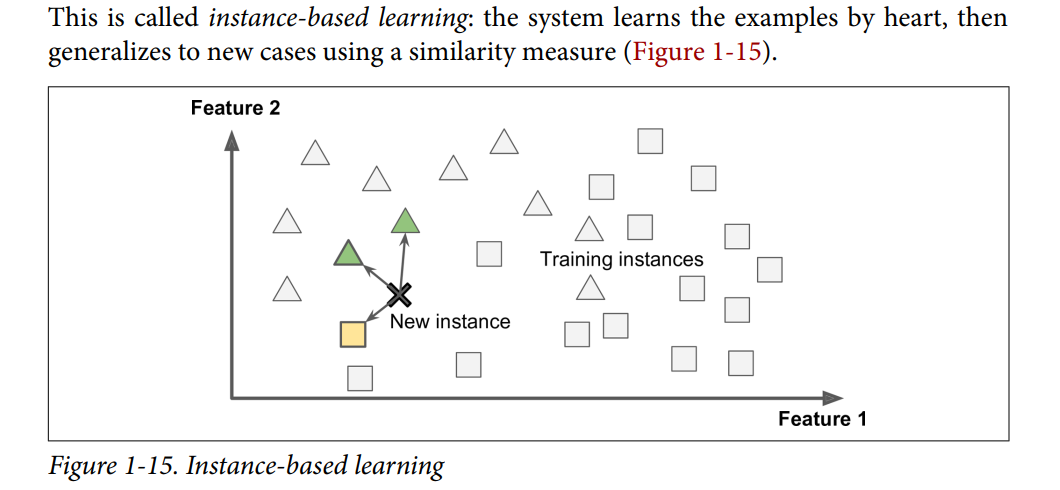
Instance based learning
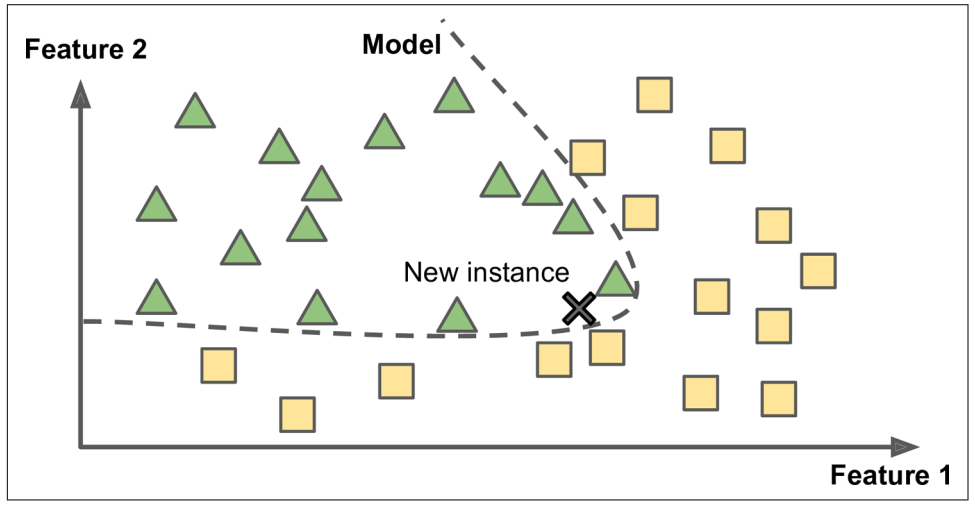
Model based learning
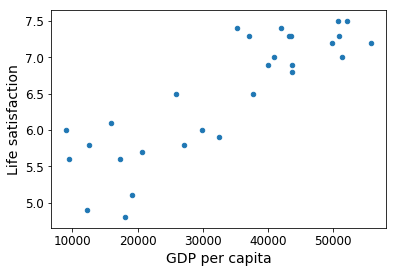
- To measure the fitness of the mdoel:
- you can specify a performance measure. define a utility function(fitness function)
- or define a cost function define how bad the model is.
- Code examples:
1 | import matplotlib |
Main Challenges of ML
Insufficient Quantity of Training Data
- The Unreasonable effectiveness of data
Nonrepresentative Training Data
- Sample selection bias
- US presidential election in 1936
Poor-Quality Data
- Outliers
- Missing a few features
Irrelevant features
- Process Feature Engineering
- feature selection
- feature extraction
- create new features by gathering new data
Overfitting the Training Data
- Regularization : constraining a model to make it simpler and reduce the risk of overfitting
degrees of freedom: the number of parameters
Hyper-parameter to control for the amount of regularization
Underfitting the Training Data
- The model is too simple