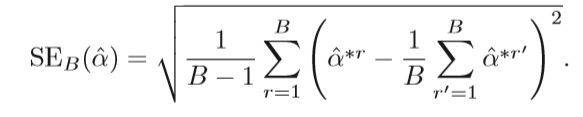- To estimate test error properly, there are different ways to do this. For example, some methods make a mathematical adjustment to the training error rate to estimate the test error rate. Other methods like cross validation, holds out a subset of the training observation from the fitting process.
- The notes will cover leave on out, k-fold, and bias-variance trade off of Cross Validation, and Bootstrap.
Cross-Validation
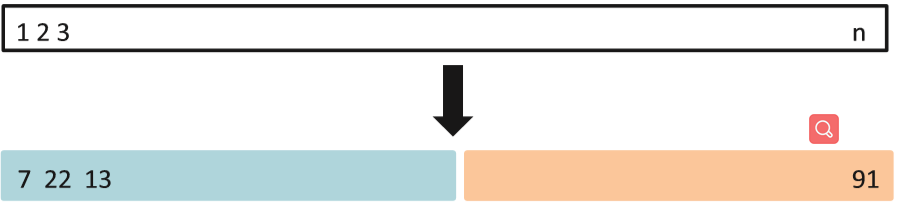
The Validation Set Approach
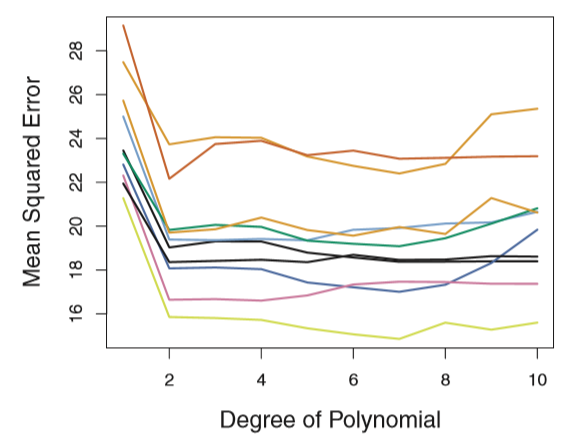
Random split the data ten times, then use each of them to test the polynomial formula of different powers.
The result:
 |
 |
|---|---|
| The approach | The result |
- Drawbacks:
- As is shown in the right column of the table, the estimate of test error is very variable
- In the validation set approach, only a subset of the observations are used to fit the model, resulting an over estimate of the test error rate compared to use the whole dataset to train the model.
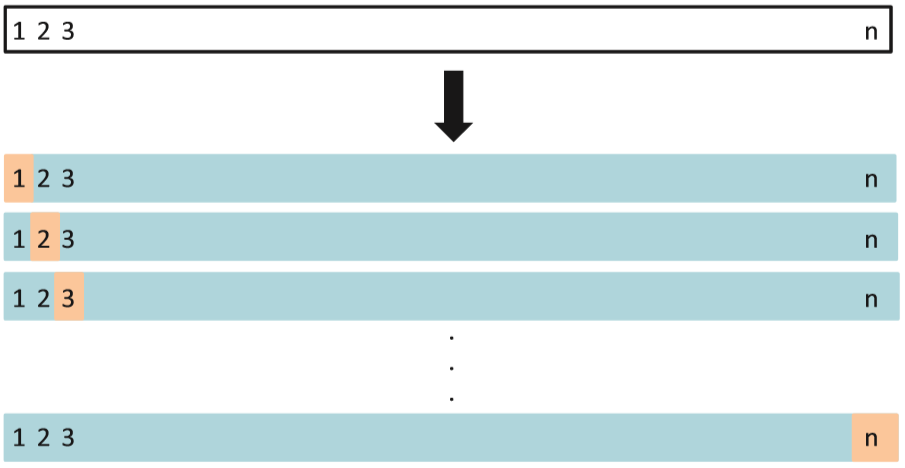
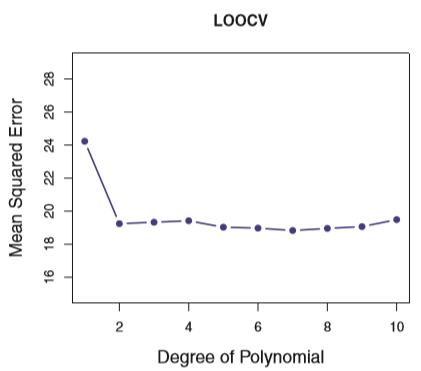
LOOCV
- The result:
 |
 |
|---|---|
| The approach | The result |
The estimate of the test error rate is: $CV_{(n)} = \frac{1}{n}\sum^n_{i=1}MSE_i$ of which, $MSE_i = (y_i-\hat{y}_i)^2$
An simplify of the LOOCV if the model is polynomial or least square linear:
- $CV_{(n)} = \frac{1}{n}\sum^n_{i=1}(\frac{y_i-\hat{y}_i}{1-h_i})^2$
- Where hi will be described later in the chapter about linear regression
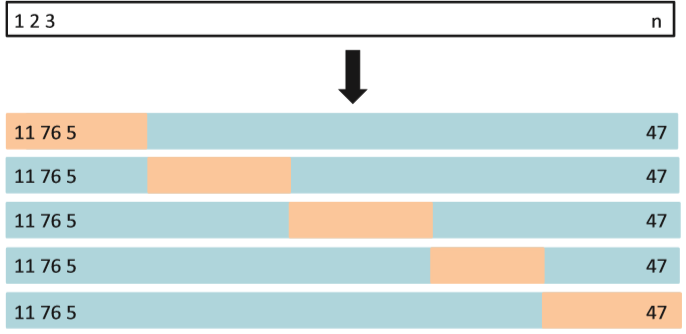
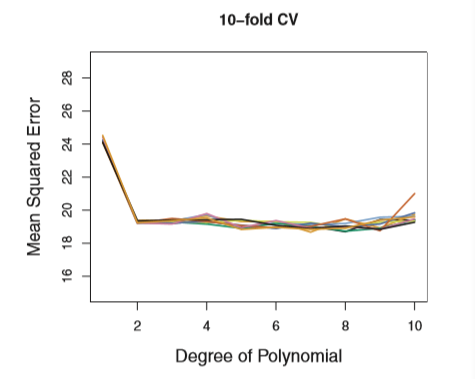
k-Fold Cross-Validation
- The result:
 |
 |
|---|---|
| The approach | The result |
- the 10-fold CV was run nine separate times, each with a different random split of the data into ten parts
Comparison between these approaches
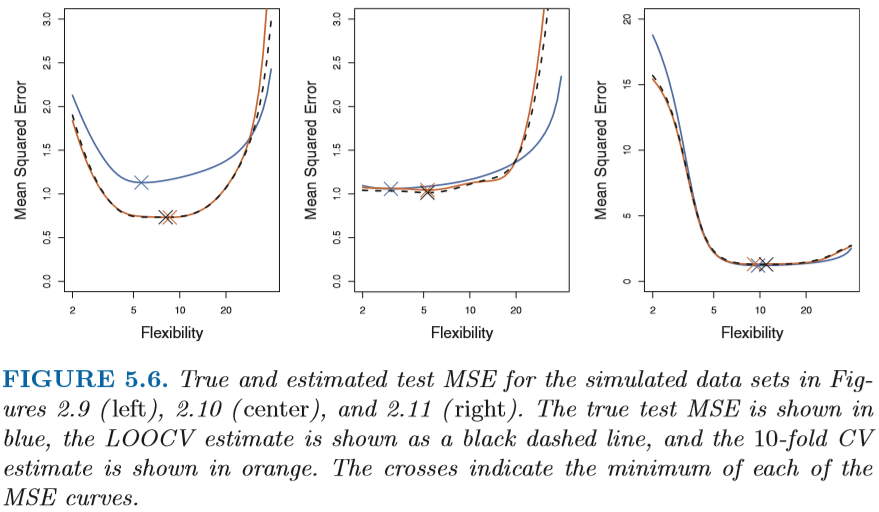
- Some times, if we only interest in the location of the parameter in order to minimize the test error instead of the test error itself, then loocv and k-fold can always produce a good result.
Bias-Variance Trade-Off of “K”
- K-Fold often gives more accurate estimates of the test error rate than does LOOCV
Bias:
- Validation set approach use only a part of the dataset, so it may be very biased to estimate test error rate.
- LOOCV give approximately unbiased estimates of the test error, since almost all the observations are used to fit the model.
- The k-fold test provides an intermediate bias in estimating the test error rate.
Variance:
- LOOCV trained n models which are highly correlated with each other, resulting in higher variance
- K-fold validation train models which are less correlated with each other.
- The insight is: the mean of some highly correlated quantities has higher variance.
The Bootstrap
An example:
Suppose we want to minimize the variance of an investment: $Var(\alpha X+(1-\alpha)Y)$
Thus $\alpha = \frac{\sigma^2_Y-\sigma_{XY}}{\sigma^2_X+\sigma^2_Y-2\sigma_{XY}}$ can minimize the above value
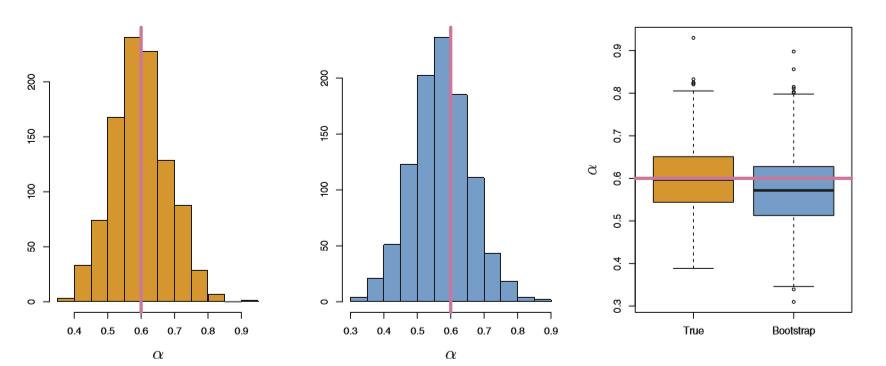
- Use 1000 times of simulation to estimate $\alpha$, and $\hat{\alpha}_r$ is very close to true $ \alpha$
- The standard deviation is $SE(\widehat{\alpha}) = \sqrt{\frac{1}{1000}\sum^{1000}_{r=1}(\hat{\alpha}_r-\bar{\alpha})^2}$
- The result of simulation is the orange one:
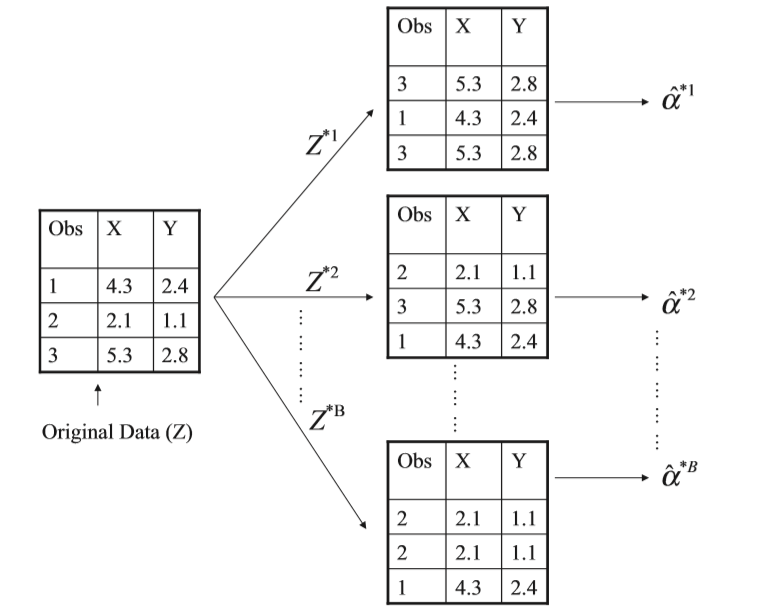
Bootstrap
- A method which repeatedly sampling from original data set
- The method is illustrated below:
- And the standard error is: