- Last Chapter introduce linear regression as a basic tool for regression analysis. For this chapter, LDA and logit model would be introduced to solve classification problems
- This notes covers: Why not Linear Probability Model?, Logistic Regression (Logit Model), Linear Discriminant Analysis, Comparison between Classification Methods
Why Not Linear Regression?
- Hard to extend the model into a qualitative response with more than two levels
- The predicted value will exceed a reasonable range.
Logistic Regression
The logistic model:
Definition:
$p(X) = \frac{1}{1+e^{\beta_0+\beta_1X}}$, which can be extend to various predictors
Manipulate the above model we get: $log(\frac{p(X)}{1-p(X)}) = \beta_0 + \beta_1X$
- The formula: $\frac{p(X)}{1-p(X)}$ is called the odds
- The left side of the equation is called log-odds or logit
- Interpretation: The rate of change in p(X) per unit change in X depends on the current value of X
Estimating coefficients
- Use maximum likelihood.
The intuition: find the best $\beta_0$ and $\beta_1$ to make the observations in the sample are most likely to be chosen from the population.
The likelihood function: $l(\beta_0,\beta_1) = \prod_{i:y_i =1}p(x_i)\prod_{i’:y_{i’}=0}(1-p(x_{i’}))$
- p-value and hypothesis test can be carried as linear regression, but $R^2$ may become meaningless
Multiple Logistic Regression
- A valid way to avoid Omitted variable bias or confounding in statistical learning
For >2 response Class
- Model both $Pr(Y=Class_1|X) $ and $Pr(Y = Class_2 | X)$
- The remaining $Pr(Y=Class_3) = 1-Pr(Y=Class_1|X)-Pr(Y = Class_2 | X)$
Linear Discriminant Analysis
- Bayes’ theorem: $Pr(Y=k|X=x) = \frac{\pi_kf_k(x)}{\sum_{l=1}^{K}\pi_lf_l(x)}$
refer to $p_k(x)$ ,which is the left-hand of the equation as the posterior.
- refer to $\pi_k$ as prior
- refer to $f_k(x)$ as density function, which is the density of x given its class k
Some insights:
- in the theorem, the prior is easier to estimate use the sample, simply count the number of observation and divided by number of all observations. Mathematically, $\widehat{prior} = \frac{n_k}{n}$
- the density however, is much more difficult. In the LDA, we estimate the density by making assumptions
- The objective of LDA is to divide two class as far as possible, and the insight is that we try to use the predictor or axises to maximize the distance between the average value of each class but minimize the variance of each class
LDA For p = 1 (one predictor)
Estimate the density
- $f_k(x) = \frac{1}{\sqrt{2\pi}\sigma_k}e^{-\frac{(x-\mu_k)^2}{2\sigma_k^2}}$
- Then taking the log of the equation: $Pr(Y=k|X=x) = \frac{\pi_kf_k(x)}{\sum_{l=1}^{K}\pi_lf_l(x)}$, we can show that it is equivalent to assigning the observation to the class for which $\delta_k(x) = x\cdot\frac{\mu_k}{\sigma^2} - \frac{\mu_k^2}{2\sigma^2}+log(\pi_k)$ is largest
Estimate $\mu_k$ and $\sigma_k$
- For each class: $\hat{\mu}_k = \frac{1}{n}\sum_{i:y_i=k}x_i$
- Then we assume that the variance of predictor is all the same for each class. $\hat{\sigma}^2 = \frac{1}{n-K}\sum^K_{k=1}\sum^{}_{y_i=k}(x_i-\hat{\mu}_k)^2$
LDA For p > 1
Assumption:
Within each class, the observations are drawn from a same multi-variate normal distribution
The covariance matrix of the density function of multi-variate normal distribution is the same for all classes.
The density:
- $f(x) = \frac{1}{(2\pi)^{p/2}|\sum|^{1/2}}e^{(-\frac{1}{2}(x-\mu)^T\sum^{-1}(x-\mu))}$
- Thus the discriminant is $\delta_k(x) = x^T\sum^{-1}\mu_k-\frac{1}{2}\mu_k^T\sum^{-1}\mu_k+log\pi_k$
Worth noticing:
- Training error will usually lower than test error. Remember to avoid overfitting when the ratio of parameters p to number of samples n is large.
- The threshold should be modified to achieve the demand instead of simply minimizing the overall error rate
Adjusting the threshold
Confusion Matrix(Of the default example)
| predicted/true | no | yes | total |
|---|---|---|---|
| no | 9644 | 252 | 9896 |
| yes | 23 | 81 | 104 |
| total | 9667 | 333 | 10000 |
overall error rate: $ = \frac{23+252}{10000}$
However: The error rate of wrongly classified those who will default $= \frac{252}{333} = 75.7\%$, which is unacceptable
- The term sensitivity of this example: True defaulters that are identified
- The term specificity of this example: Non-defaulters that are correctly identified
So, we can say that the sum of sensitivity and specificity are the rate that a classifier made right decision.
The low rate of sensitivity actually comes from the Bayes Classifier: we classify an observation to the default class if $Pr(default = Yes|X=x) > 0.5$, however, we can modify this to 0.2 if we want to increase the sensitivity at a cost of the specificity.
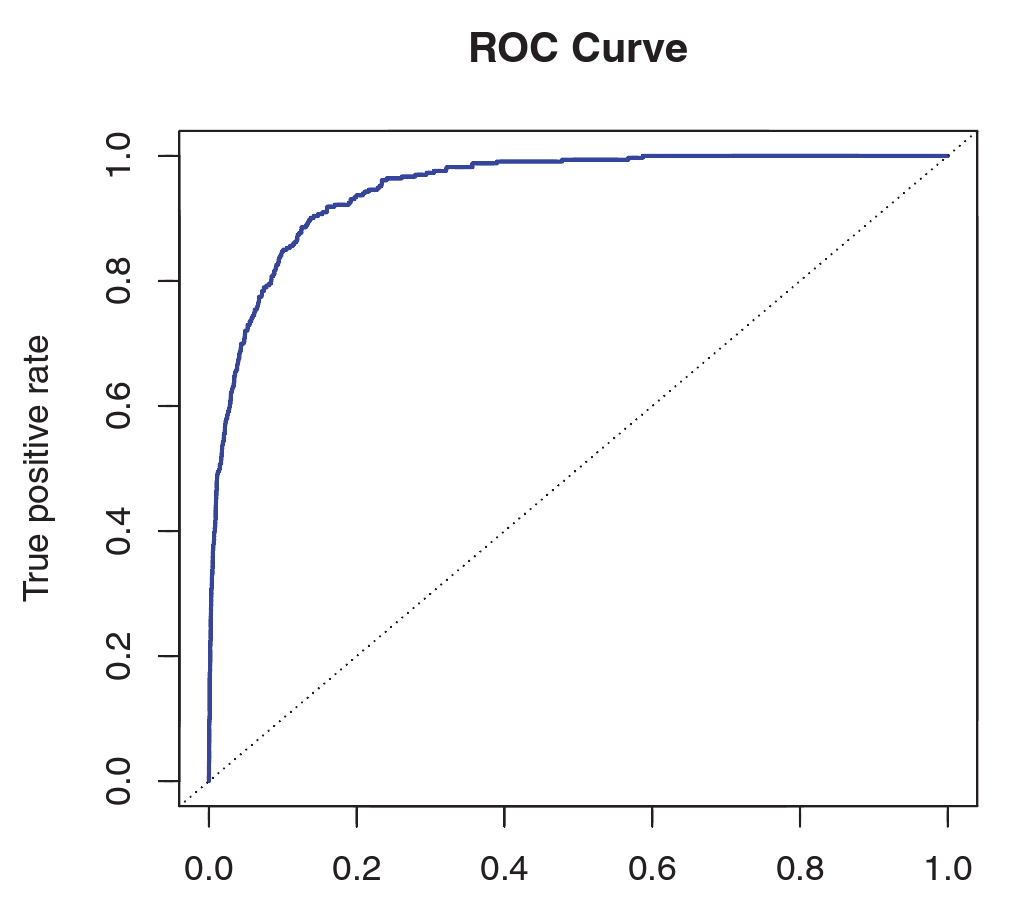
ROC Curve
Roc curve is a graphic for simultaneously displaying the two types of errors for all possible thresholds
It only works for two class classifier, the dashed line represents a random classifier. The best classifier should be the point (0,1)
| true/predicted | - or null | + or non-null | total |
|---|---|---|---|
| - or null | TN | FP | N |
| + or non-null | FN | TP | P |
| total | N* | P* |
| NAME | DEFINITION | SYNONYMS |
|---|---|---|
| False Pos. rate | FP/N | type-I error, 1-Specificity |
| True Pos, rate | TP/P | 1-Type II error , power, sensitivity, recall |
| Pos. Pred. value | TP/P* | Precision,1-false discovery proportion |
| Neg. Pred. value | TN/N* |
Quadratic Discriminant Analysis
QDA assums that the observations from each class are drawn from a Gaussian distribution, and plugging estimates for the parameters into Bayes’ theorem that each class has its own covariance matrix.
Thus QDA involves plugging estimates for $\sum_k, \mu_k$ and $\pi_k$
- QDA estimates $K \times \frac{p(p-1)}{2}$ parameters, which is much more flexible than LDA
- LDA may be better if there are fewer observations, but if the training set is large, the variance of the classifier is not a major concern(Use QDA)
Comparison of Classification Methods
As for logistic regression and LDA: Both methods are linear of X, the only difference lies in Logistic Regression use Maximum likelihood to estimate the parameters, while LDA makes an assumption of normal distribution and estimate the mean and variance
If the dicision boundary is highly non-linear, then KNN is out-performed.
- QDA serve as a compromise between the non-parametric KNN method and the linear LDA
- The flexibility level of KNN should be carefully chosen